AMD正式发布了备受期待的Instinct MI300系列,在人工智能领域也有了自己的秘密武器,MI300A APU和MI300X GPU两个家庭成员,是不是能打,我们还要持续观察。
MI300A作为APU,将CPU与GPU IP整合在一起,AMD在这一设计上实现了引领水平的集成度,核心数量相对较少,但集成度相更高。
Instinct MI300X,是专为与NVIDIA H100正面竞争而设计的GPU型号。MI300X显示出OAM/SXM组件的外观。

一)规格和性能比较
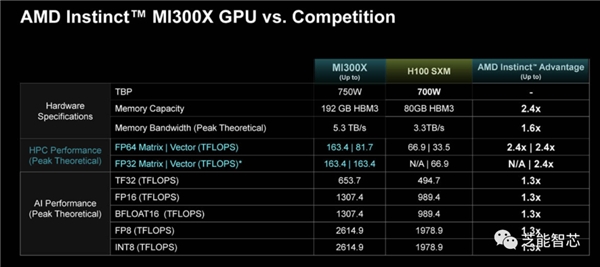
MI300X与H100 SXM的对比中,AMD展示出在许多高端数据上超过2倍的性能,在人工智能领域的表现更是达到1.3倍。

MI300X的性能令人瞩目,具有每个加速器192GB HBM3、大量内存带宽和Infinity Fabric带宽,在HPC关键计算指标上的性能相当于NVIDIA H100的2.4倍,在人工智能领域更是达到1.3倍。

具有1530亿个晶体管的MI300X做成了一块庞大的芯片,适用于超级计算应用。
特别是在AI市场崛起之际,AMD开始要发力了,大客户都买不到GPU,都排队等着给英伟达订单,这是个巨大的机会。

二)架构深入
MI300X的基础是CDNA 3芯片,在架构上展现了其对人工智能的关注,具备128通道交错HBM3存储器接口和256MB Infinity Cache,MI300X在内存子系统方面表现出色。


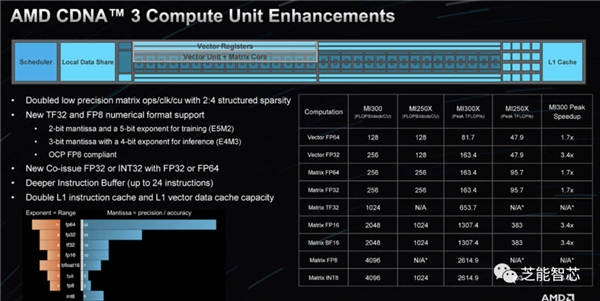
AMD通过MI300X OAM平台展示了其与NVIDIA的竞争力,尽管没有使用NVSwitches,但在功耗上却表现得相当竞争力十足。

MI300X不仅拥有 GPU,还有 8 个用于计算的 XCD、4 个 IO 芯片、8 个 HBM3 堆栈、256MB 缓存和 3.5D 封装

MI300X将其中的8个GPU放置在OAM UBB上,构建了一台8路GPU系统。
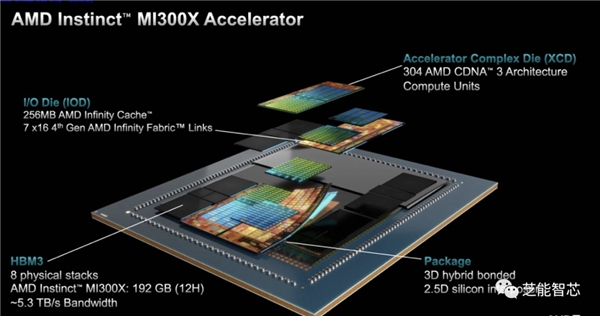
128 通道交错 HBM3 存储器接口。MI300X还拥有 256MB Infinity Cache,峰值带宽为 17TB/s

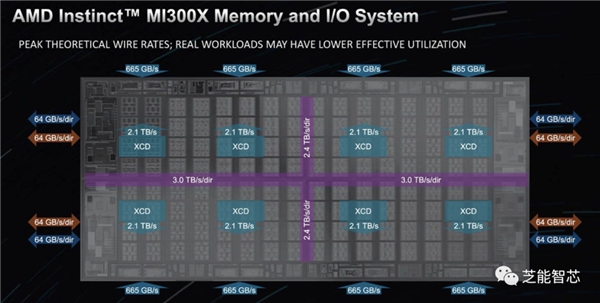
OAM 平台被设计为 SXM 的超大规模替代方案,不使用 NVLink 开关。

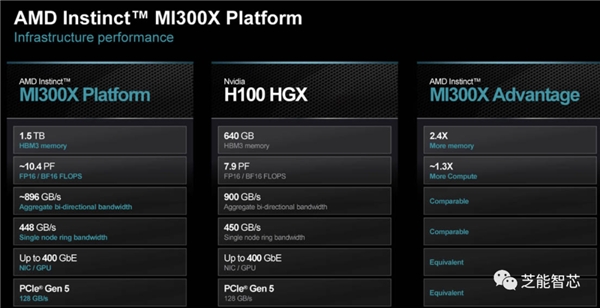
以下处处是针对英伟达的对标
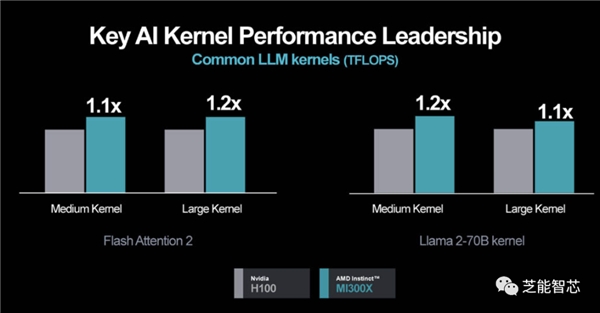
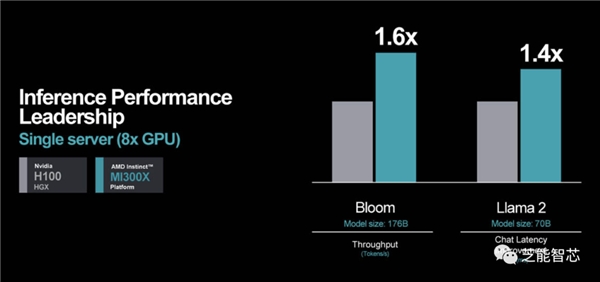


AMD已经与多家OEM厂商签约,提供MI300X系统。在合作伙伴方面,微软和甲骨文云都表示了与AMD的深度合作,展示了MI300X在云计算领域的广泛应用前景。


巨大的市场机会和目前英伟达的垄断地位给了AMD的机会, Instinct MI300系列的发布通过深度集成的设计,为用户提供了更高效的解决方案。在AI时代的崛起中,AMD Instinct MI300系列也让我们看到在这个领域不是一家在战斗。